

Large Language Model leiten eine neue Ära der digitalen Kommunikation und Automatisierung ein. In der Interaktion zwischen Mensch und Maschine erlauben sie neuartige Steuerung über Sprachbefehle. LLMs fungieren somit als Vermittler zwischen der Komplexität der menschlichen Sprache und der digitalen Verarbeitung. Ihre Entwicklung ähnelt der Bedeutung von Betriebssystemen, die als essenzielle Schnittstelle zwischen Hardware und Software dienen.
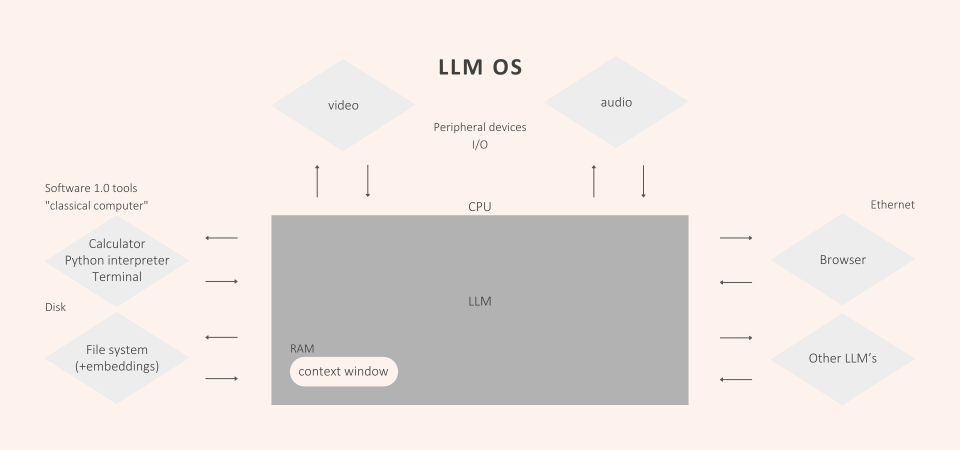
Gerade für Unternehmen bieten LLMs viele Chancen um Arbeitsprozesse zu erleichtern. Allerdings birgt diese neue Technologie auch Risiken, die es bei der Nutzung zu beachten gibt.
In diesem Artikel möchte ich auf diese eingehen und Möglichkeiten aufzeigen, Sicherheitsrisiken zu minimieren. Wichtig ist hier zu betonen, dass der Artikel nur eine Momentaufnahme bietet. Diese neue Technologie ständig im Wandel ist und mit Weiterentwicklungen können neue Sicherheitsrisiken hinzukommen.
Was sind LLMs und wie werden diese eingesetzt?
Die großen Sprachmodelle (eng. Large Language Models oder kurz: LLMs) sind ein zentraler Bestandteil der generativen Künstlichen Intelligenz (GenAI). Sie revolutionieren die Art und Weise, wie wir mit Maschinen kommunizieren.
Mit Hilfe von riesigen Datensätzen erlernen und verstehen LLMs wie ChatGPT die menschliche Sprache. So wird eine eine intuitive und effiziente Interaktion zwischen Menschen und Technologie möglich.
LLMs finden in verschiedensten Bereichen Anwendung. Dazu zählen Bereiche wie Kundenservice, Content-Erstellung und Bildung. Durch das kontinuierliche Lernen verbessern sie sich mit jeder Interaktion.
OWASP Top 10 Sicherheitsrisiken für LLMs
Diese innovative Technologie bringt jedoch neue Risiken mit sich. Auch hierbei kann ein Vergleich zwischen LLMs mit Betriebssystem gezogen werden. Sobald in Geschäftsprozesse integriert, sind spezifische Sicherheitsvorkehrungen notwendig.
Laut einer Studie von Adesso erkennen 78% der Führungskräfte in Deutschland die Potenziale von GenAI für ihr Geschäftsmodell. Eine IBM-Studie verdeutlicht wiederum Verunsicherungen dieser bezüglich generativer AI. So gaben 4 von 5 Führungskräften Bedenken bezüglich der Vertrauenswürdigkeit zu haben - insbesondere bezüglich der Sicherheit.
Wie kann Ihr Unternehmen die Vorteile von LLMs nutzen und gleichzeitig die Sicherheitsrisiken dabei minimieren?
Eine Orientierung hierzu bietet die Top10 Sicherheitsrisiken für LLMs von Open Web Application Security Project (OWASP):
-
Prompt injection
-
Insecure Output Handling
-
Training Data Poisoning
-
Model Denial of Service
-
Supply Chain Vulnerabilities
-
Sensitive Information Disclosure
-
Insecure Plugin Design
-
Excessive Agency
-
Overreliance
-
Model Theft
Um diese Risiken besser zu verordnen, werfen wir einen Blick auf die wichtigsten Bausteine der LLM-Applikation. Den Anfang bilden Daten. Diese Daten stammen aus unzähligen verschiedenen Quellen.
Wir nutzen diese, um unsere Modelle zu trainieren, welche die nächste Komponente dieses Frameworks sind. Die letzte Komponente bildet die Verwendung durch die Nutzer*innen.
Folgendermaßen hängen diese drei zusammen: Wir verwenden die Daten, um das Modell zu trainieren und letztendlich verwenden die Nutzer*innen wird das Modell, um eine Vorhersage zu erhalten.
Die Vorhersage ist der Punkt, an dem wir unseren Output erhalten.
Tatsächlich müssen wir uns ansehen, wie wir jede einzelne Komponente dieser Struktur sicher machen können
-
Wie sichere ich die Daten?
-
Wie sichere ich das Modell?
-
Wie sichere ich die Nutzung?
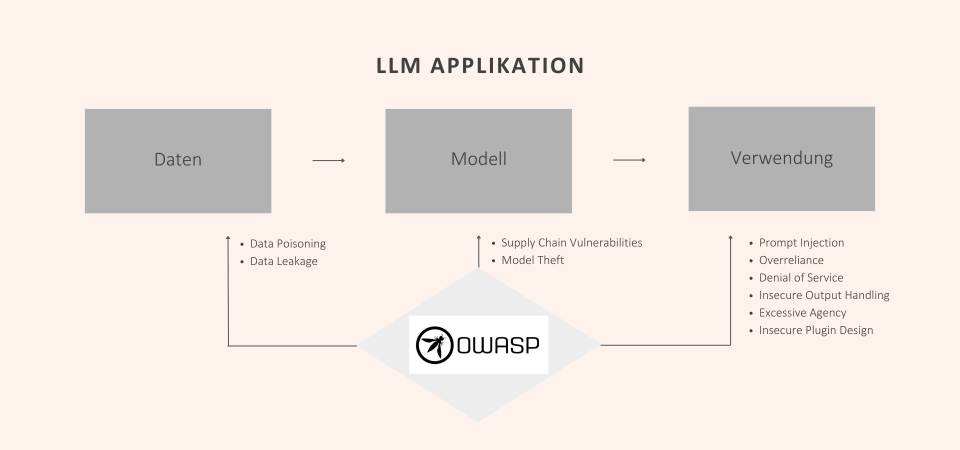
Key Komponenten der LLM-Applikation
Daten
Die Daten formen die Basis, auf der intelligenten LLM-Systeme lernen. Mit zunehmender Integration von LLMs in geschäftskritische Anwendungen steigt auch das Risiko einer Datensicherheitsverletzung. Insbesondere zwei Arten von Angriffen stellen eine ernsthafte Bedrohung dar: Datenvergiftung und Datenlecks.
Datenvergiftung – auch als "Data Poisoning" bekannt – bezeichnet eine subtile, aber effektive Methode, die Integrität eines LLMs zu kompromittieren. Angreifer*innen fügen hierzu dem Trainingsdatensatz absichtlich falsche oder irreführende Stichproben (Informationen) hinzu. Dabei können die Angreifer*innen zwei Ziele bei der Manipulation des Modells verfolgen:
-
Dieses soll fehlerhafte Vorhersagen treffen.
-
Dieses soll bestimmt, von den Angreifenden gewünschte Verhaltensweisen annehmen.
Die Bandbreite der Folgen variieren enorm – von geringfügigen Ungenauigkeiten bis hin zu gravierende Sicherheitsrisiken, die das Vertrauen in das Modell untergraben z.B. die Exfiltration. Unter einem Exfiltrationsangriff versteht man, das jemand in dieses System einbricht und Daten daraus entwendet.
Eben diese Daten könnte eine große Menge sensibler Informationen enthalten. Eine andere Variante davon ist die Datenleckage. Im Vergleich zur Exfiltration ist diese eher unbeabsichtigt.
Allerdings bleibt der Effekt derselbe. Sensiblen Daten gelangen in fremde Hände. Im schlimmsten Fall sogar extrem viele sensible Daten. Schließlich benötigt man hiervon eine Menge, um das Modell genauer und für den spezifischen Anwendungsfall effizienter zu machen.
Die Konsequenzen reichen von Datenschutzverletzungen bis hin zum Verlust von geistigem Eigentum. Weiterhin können diese erhebliche finanzielle und rechtliche Folgen nach sich ziehen.
Falsche Konfigurationen oder unzureichende Zugriffskontrollen begünstigen solche Lecks. Ich greife hier nochmal den Vergleich zu Betriebssystem auf. Was für diese Schutz durch Firewalls, Antivirenprogramme und regelmäßige Sicherheitsupdates darstellt, sind bei LLM sorgfältige Datenselektion und kontinuierliche Überwachung.
Modell
Von Desktop-Betriebssystemen kennen wir die Unterscheidung zwischen proprietären Systemen wie Windows sowie MacOS und Open-Source-Systemen auf Linux-Basis.
Diese Differenzierung gibt es auch bei Large Language Modellen. Zu den proprietären Modellen zählen u.a.:
-
ChatGPT (OpenAI)
-
Gemini (Google)
-
Claude (Anthropic)
Bei Open-Source sind folgende Beispiele zu nennen:
-
Llama (Meta)
-
Mistral
-
Command R+ (Cohere)
-
ein großes Ökosystem von Huggingface (mit mehr als 300.000 Modellen)
Open-Source-LLMs bieten einzigartige Sicherheitsvorteile für ihre Nutzer*innen. Durch die Transparenz der Architektur und des Codes können Sicherheitslücken schneller identifiziert und behoben werden. Dieses Fine-Tuning ermöglicht eine Anpassung an spezifische Anforderungen. Aber auch eine gezieltere Kontrolle über die generierten Inhalte wird einfach, was die Risiken von Fehlinformationen reduziert.
Ein weiterer Vorteil von Open-Source Modell sind die Communities und Expert*nnen. In der Regel prüfen diese in wiederkehrenden Abständen umfassend den offenen Quellcode und sichern diesen somit.
Beispiele sind auch die hierzu von eben diesen Communities entwickelten Benchmarks wie Truthful AI. Ein Treiber für die Entstehung war die rasante Entwicklung im Bereich der Open-Source-LLMs. Diese benötigt eine kontinuierliche Beobachtung der Fortschritte und Risiken durch explizit dafür entwickelte Überwachungs- und Bewertungssysteme.
All diese Aspekte machen Open-Source-LLMs zu einer vertrauenswürdigen Wahl für Unternehmen, welche einen hohen Wert auf Sicherheit, Anpassungsfähigkeit und Innovation legen.
Verwendung
Auch bei der Nutzung von LLMs gibt es Risiken wie:
-
semantische Angriffe (Prompt Injektion)
-
Ausgabebehandlung (Insecure Output Handling)
-
Anwendung-Verfügbarkeit (Model Denial of Service)
Diese Risiken kann man mit der spekulativen Ausführung wie bei traditionellen Betriebssystemen vergleichen.
Das Ziel von Prompt Injektion ist es durch Manipulation der LLM, unerwünschte oder schädliche Ausgaben zu erzeugen. Bei einem Angriff verwenden die Angreifenden dazu speziell formulierte Eingabeaufforderungen (Prompts).
Diese Art der Attacke versucht, die Sicherheitsmaßnahmen des Modells zu umgehen. Dabei "überreden" die Angreifenden die LLM, Informationen preiszugeben, Fehlinformationen zu verbreiten oder Aktionen auszuführen, die für die Angreifenden von Nutzen sind.
Welche Herausforderungen ergeben sich bei der Abwehr von Prompt Injektion? LLMs müssen die Fähigkeit besitzen, aus einer Vielzahl von Eingaben zu lernen und darauf zu reagieren. Entscheidend hierfür sind:
-
eine sorgfältige Überprüfung und Einschränkung der Benutzereingaben
-
gekoppelt mit fortgeschrittenen Techniken des maschinellen Lernens zur Erkennung und Abwehr von manipulativen Prompts.
Insecure Output Handling bezieht sich auf das Risiko, dass die von einem LLM generierten Ausgaben schädliche oder irreführende Informationen enthalten könnten. Ohne angemessene Validierung können diese Outputs die Tür für eine Vielzahl von Angriffen öffnen:
-
Verbreitung von Fehlinformationen
-
Phishing-Versuche
-
Beeinträchtigung der Datenintegrität
Wie lässt sich dieses Risiko minimieren?
Zunächst sollten alle Ausgaben sorgfältig auf potenziell schädliche Inhalte überprüft werden. Weiterhin empfiehlt sich der Einsatz von Mechanismen, die gewährleisten, dass alle Outputs den Richtlinien für Sicherheit und Genauigkeit entsprechen.
Der dritte Angriffstyp ist die Dienstverweigerung (Model Denial of Service). Wenn jemand genügend komplexe Angriffe in das System sendet, könnte es sein, dass das System ins Stocken gerät. Fragen lassen sich tendenziell schneller stellen als die Zeit, die das System für eine Antwort benötigt. Wenn man eine Menge davon senden, wird das System überfordert und kann nicht mehr mithalten.
Risikominimierung durch mehrschichtige Sicherheitsmaßnahmen
Dabei ist es mit der Abdeckung dieser Komponenten noch nicht getan. Um die Sicherheit von LLM-Anwendungen zu gewährleisten, ist ein mehrschichtiger Ansatz erforderlich. Dieser sollte technische und organisatorische Maßnahmen kombinieren. Dazu gehören:
-
Misstrauen als Prinzip: Outputs von LLMs immer kritisch prüfen.
-
Datenvalidierung: Inputs und Outputs erfordern eine sorgfältige Überprüfung auf schädliche Inhalte.
-
Zugriffskontrollen und Verschlüsselung: Essenziell für den Schutz sensibler Daten.
-
Monitoring: Die Überwachung von Systemaktivitäten hilft, Anomalien frühzeitig zu erkennen.
-
Datenschutz durch Design: Sicherheit und Datenschutz müssen von Anfang an einen integralen Bestandteil der Entwicklung sein.
-
Staff-Training: Bildung und Sensibilisierung der Nutzer*innen sind Schlüssel, um Fehlinformationen und Missbrauch zu verhindern.
Die Welt der LLMs ist voller Möglichkeiten, stellt Unternehmen aber auch vor neue Sicherheitsherausforderungen. Damit Ihr Unternehmen das volle Potenzial von Large Language Models ausschöpfen können, müssen Sie zwei Dinge beachten. Ein tieferes Verständnis und aufgebaute Expertise zu dieser Technologie ist ein Muss. Vermeiden sie die oben genannten Risken, indem Sie entsprechenden Sicherheitsmaßnahmen treffen.



