

Optimierung in Echtzeit: Wie KI und Caching-Strategien die Reaktionszeiten revolutionieren
Die Abfragen gegen die OpenAI-API sind hinsichtlich der Ausführungszeit und ab einer bestimmten Anzahl von Abfragen auch aus finanzieller Sicht teuer.
Die Frage ist: Kann der Prozess der Lösung von KI-Aufgaben beschleunigt werden? Und gibt es Möglichkeiten, die Kosten zu senken?
Wie optimieren Caching-Strategien den OpenAI-API-Prozess?
Abfragen an die OpenAI-API brauchen Zeit. Es kann nichts dagegen getan werden, um den Prozess zu beschleunigen. Übrig bleiben nur noch Caching-Strategien und Automatisierungen.
Durch die Erstellung einer Hash-Tabelle mit den Artikeldaten kann ein effizienter Vergleich von Artikeln gewährleistet werden. Dies hilft dabei zu bestimmen, ob für einen Artikel eine neue Abfrage an die OpenAI-API gesendet werden muss. Mithilfe von Cron-Jobs kann die Hash-Tabelle automatisch und über Nacht erstellt oder aktualisiert werden.
Auch Abfragen gegen die OpenAI-API könnten auf diese Weise automatisiert und vorab berechnet werden. Letztendlich müssen die Möglichkeiten von Anwendungsfall zu Anwendungsfall geprüft werden. Es gibt keine universelle Strategie für das Caching.
KI und Caching-Strategien: Maximale Leistung, minimale Kosten
ChatGPT ist ein textbasierter KI-Assistent. Mithilfe von ChatGPT können Aufgaben mit hinreichender Komplexität gelöst werden. Eine der offensichtlichsten Einschränkungen ist die Beschränkung der verfügbaren Token. Darüber hinaus ist es bei Aufgabentypen wie Berechnungen, Schätzungen und anderen mathematisch anspruchsvollen Problemen schwierig oder unmöglich, korrekte oder konsistente Antworten zu erhalten.
Es dauert lange, einen API-Aufruf gegen OpenAI durchzuführen und die entsprechende Antwort zu erhalten.
Mit zunehmenden Anfragen an OpenAI steigen die Kosten. Die Preise variieren je nach verwendeten Modellen. So sind Abfragen, die mit dem Modell ChatGPT-3.5-turbo gelöst werden, günstiger als die mit ChatGPT-4-turbo.
Daher ist es sinnvoll, Anfragen an die OpenAI-API zu minimieren und über eine Strategie zum Zwischenspeichern bereits abgefragter Daten nachzudenken. In diesem Artikel sollen mögliche Caching-Strategien betrachtet werden.

KI und Caching-Strategien: OpenAI-Anfragen mit intelligentem Prompting optimieren
Der einfachste Ausgangspunkt hinsichtlich der Optimierung ist das sogenannte Prompting. Durch eine möglichst genaue, aber einfache Formulierung der zu lösenden Aufgabe ist es möglich, präzisere Ergebnisse zu erzielen. Darüber hinaus können Regeln für das Format der Antwort festgelegt werden.
Mit einem guten Prompt lässt sich sicherstellen, dass – bei geeigneter Aufgabe – konsistente Antworten in der gewünschten Struktur zurückgegeben werden. Der Schlüssel zu einem guten Prompting liegt offenbar in der klaren Definition der Aufgabe, der Bereitstellung von Regeln und dem gewünschten Ausgabeformat.
Allerdings führt eine Optimierung des Prompts an dieser Stelle weder zu einer schnelleren Bearbeitung noch zu einer Kostenminimierung.
Ein weiterer Ansatzpunkt für eine schnellere Bearbeitung komplexer Aufgaben ist die Zerlegung in Teilaufgaben. Diese Aufteilung verlängert jedoch die Übermittlung der endgültigen Antwort. Dies liegt vor allem daran, dass mehrere Abfragen durchgeführt werden müssen, um zum gewünschten Ziel zu gelangen. Die erhöhte Anzahl an Abfragen steigert die Kosten.
Einige Leitfäden empfehlen, den Prompt zu diesem Zweck vorab zu verarbeiten. Die hierfür notwendigen Schritte sind in der folgenden Abbildung zu sehen.
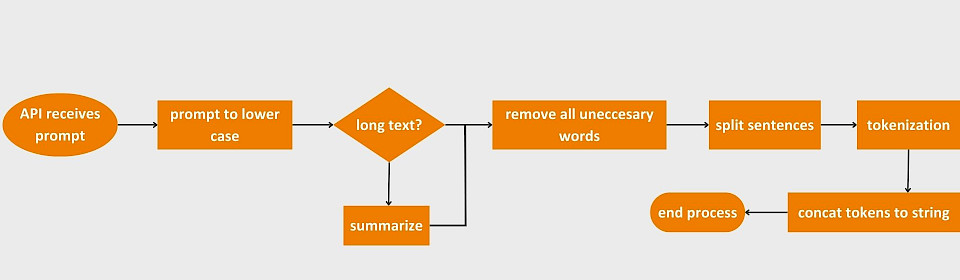
Bei einer Diskussion mit Teamkolleg*innen wurde deutlich, dass genau diese Optimierung bereits aufseiten von OpenAI stattfindet. Daher führt auch die Vorverarbeitung nicht zum gewünschten Ergebnis. Das liegt daran, dass der auf diese Weise vorverarbeitete Prompt von OpenAI noch einmal vorverarbeitet wird.
In dem besagten Meeting kamen wir zu dem Schluss, dass die Optimierung für jeden Anwendungsfall spezifiziert werden sollte. Im Folgenden werden einige Beispiele für Anwendungsfälle und deren mögliche Optimierungen betrachtet.
Anwendungsfallspezifische Optimierungen
Um die Optimierungsstrategien für die einzelnen Anwendungsfälle zu berücksichtigen, muss zunächst entschieden werden, ob das Problem tatsächlich mit ChatGPT gelöst werden kann. Erfolgt die Lösung durch eine eigene Implementierung, bleibt die Überlegung, ob die Antwort zwischengespeichert werden soll. Dadurch können bereits verarbeitete Daten für andere Anwendungsfälle genutzt werden und ermöglicht Abfragen gegen die OpenAI-API.
Vorbedingung
Für ein effektives Caching empfiehlt es sich, die Artikel in aufbereiteter Form in einer Datenbank abzulegen. Der Aufbau sollte wie folgt gestaltet sein:
documentId
documentTitle
documentSubTitles
documentParagraphs
titleHash
subTitlesHash
paragraphsHash
12
'A Titel'
['subtitle 1', 'subtitle 2']
['p 1', 'p 2']
433rtfz8sd
dn7afszdfz
7xcas8d7x6
Dies mag zunächst wie eine unnötige Duplizierung von Artikeldaten erscheinen, hat aber durchaus relevante Vorteile.
Wird eine Anfrage an eine Middleware-API gesendet, um etwas zu berechnen oder zu generieren, kann anhand dieser Tabelle schnell festgestellt werden, ob und was sich am Artikel geändert hat. Es müssen lediglich die Hash-Werte des Artikeltitels, der Artikeluntertitel und des Artikelabsatzes ermittelt und mit den gespeicherten Hash-Werten aus der Datenbank verglichen werden.
Ist der Artikel noch nicht in dieser Datenbank gespeichert, handelt es sich um einen neuen Artikel. Dieser muss in der Datenbank gespeichert werden. Außerdem erfordert er eine Berechnung oder eine Abfrage an die OpenAI-API.
Berechnung von Ähnlichkeiten
Angenommen man liest zwei kurze, nicht zusammenhängende Text, zum Beispiel zwei Märchen. Wie lässt sich feststellen, dass die beiden Texte ähnlich sind?
Spontan würde man die Ähnlichkeit anhand von Thema, Struktur, Charakteren und Stilmitteln einordnen. Aber das kann einem Programm nicht vermittelt werden. Aus diesem Grund gibt es sogenannte String-Matching-Algorithmen. Diese versuchen, die Ähnlichkeit von Texten festzustellen, indem sie beispielsweise die Häufigkeit von Wörtern ermitteln.
Sie können auch berechnen, wie viele Schritte erforderlich sind, um ein Wort in ein anderes umzuwandeln. Letztlich wird es aber immer notwendig sein, das Ergebnis noch einmal zu überprüfen.
Besonders im redaktionellen Kontext kann die Feststellung von Ähnlichkeiten zwischen Texten in vielerlei Hinsicht angewandt werden. Beispielsweise ließe sich die Ähnlichkeit zwischen verschiedenen Artikeln ermitteln, um Redakteur*innen passende Teaser zu liefern. Die Frage ist, ob der Einsatz von ChatGPT für diesen Anwendungsfall geeignet ist. Für diesen Artikel wurde zuerst mit ChatGPT-3.5 und dann mit ChatGPT-4 gearbeitet.
Mit der richtigen Eingabeaufforderung und dem String-Matching-Algorithmus ist es möglich, die Ähnlichkeit von ChatGPT bestimmen zu lassen. Allerdings bleibt das Problem bestehen, dass die Abfrage Zeit und Geld kostet.
Deshalb wird für die Ähnlichkeitsbestimmung ein String-Matching-Algorithmus verwendet. Der Einsatz eines String-Matching-Algorithmus bietet zwei Vorteile. Einerseits ist die Auswertung konsistent und man kann selbst einen passenden Algorithmus auswählen. Andererseits stehen bereits verschiedene Bibliotheken zur Verfügung.
Um die Ähnlichkeit von Artikeltiteln zu ermitteln, wird die Levenshtein-Distanz verwendet. Durch die Verwendung eines String-Matching-Algorithmus werden bereits die Abfragen gegenüber OpenAI eingespart. Das bedeutet, dass kein Prompt entwickelt und optimiert werden muss oder durch die lange Reaktionszeit von OpenAI eine Verlangsamung entsteht.
Die Laufzeit der Levenshtein-Distanz kann durch Modifikation des Algorithmus verbessert werden. Welcher String-Matching-Algorithmus für welche Anwendungsfälle am besten geeignet ist, muss an anderer Stelle entschieden und evaluiert werden.
Wenn man zu einem Artikel 'a' nach 'n' vielen ähnlichen Artikeln sucht und diese zurückgeben möchte, lässt sich diese Aufgabe mithilfe der Hash-Tabelle leicht lösen. Es müssen lediglich die Ähnlichkeiten zwischen den Hash-Werten des Elements 'a' und den 'n'-vielen anderen Elementen bestimmt werden. Sobald 'n' Elemente mit ausreichender Ähnlichkeit gefunden wurden, müssen nur die entsprechenden 'documentIds' zurückgeben werden.
Bilder generieren
Die Frage, ob es sich hierbei um eine Aufgabe für ChatGPT, Data Mining oder ähnliches handelt, stellt sich an dieser Stelle nicht. Offensichtlich ist ChatGPT dafür prädestiniert. Wichtig ist, dass die Bildgenerierung erst ab ChatGPT-4 unterstützt wird.
Es ist bereits bekannt, dass sich die Abfragezeiten gegenüber der OpenAI-API nicht verbessern lassen. Die Frage lautet daher: Ist es möglich, eine Form der Vorverarbeitung oder des Cachings zu verwenden, um Kosten und Antwortzeiten zu minimieren?
Damit ChatGPT-4 ein Bild generiert, muss zunächst eine Beschreibung des zu generierenden Bildes erstellt werden. In einer zweiten Abfrage wird diese verwendet, um das Bild zu generieren.
Als erstes stellt sich die Frage, was passieren soll, wenn der Redakteur oder die Redakteurin für denselben Artikel ein weiteres Bild generieren möchte. Bekommt er oder sie als Antwort ein anderes oder dasselbe Bild?
Soll die Anfrage dasselbe Bild zurückgeben, kann die gesamte ChatGPT-Antwort zwischengespeichert werden. Soll anderes Bild generiert werden, könnte man zumindest die Bildbeschreibung cachen. Das halbiert die Antwortzeit.
Wenn für einen Artikel eine Anfrage zur Bildgenerierung an die Middleware-API gesendet wird, kann wie folgt vorgegangen werden:
- Befindet sich dieser Artikel bereits in der Hash-Tabelle, prüft das System, ob sich der Artikelinhalt geändert hat. Ist dies der Fall, wird die Hash-Tabelle entsprechend aktualisiert.
- Wenn sich das Element in der Hash-Tabelle befindet und sich nicht geändert hat, muss nichts aktualisiert werden.
- Befindet sich der Artikel nicht in der Hash-Tabelle, wird ein neuer Eintrag erstellt.
Die folgende Datenbank wird zum Zwischenspeichern generierter Bilder erstellt.
documentId
generatedImageDescription
generatedImage
12
'A generated image description'
imgUrl
Vor der Abfrage gegen die OpenAI-API prüft das System, ob für den Artikel bereits ein Bild generiert wurde. Ist dies nicht der Fall, müssen die Bildbeschreibung und das Bild zunächst über die OpenAI-API generiert werden. Die Antworten auf die Abfrage werden in der Datenbank gespeichert und das Bild zurückgegeben.
Wenn für den Artikel bereits ein Bild generiert wurde, kann überprüft werden, ob sich am Artikel etwas geändert hat oder nicht. Hat sich nichts geändert, kann der entsprechende Eintrag aus der Datenbank zurückgeben werden.
Texte generieren
Einige Anwendungsfälle lassen sich unter der Textgenerierung zusammenfassen. Beispiele hierfür sind die Generierung von Untertiteln, Zusammenfassungen und SEO-Tags.
Die Frage, ob das eine Aufgabe für ChatGPT oder für einen separaten Algorithmus ist, lässt sich nur schwer beantworten. Natürlich ist ChatGPT dafür prädestiniert. Andererseits gibt es Ansätze durch String-Algorithmen in Verbindung mit Dictionaries. Um Kosten und Aufwand bei der Entwicklung gering zu halten, wird für die Lösung solcher Aufgaben ChatgGPT verwendet.
Im Wesentlichen ist die Caching-Strategie analog zum vorherigen Fall. Für jede Aufgabe wird eine Datenbank zum Zwischenspeichern erstellt. Eingehende Artikeldaten werden mit den Daten aus der Hash-Tabelle verglichen. Anschließend werden die Fälle verarbeitet.
Automatisierung und Vorverarbeitung
Die hier gestellte Frage ist relativ einfach: Gibt es Schritte und Berechnungen, die ohne Abfragen an die Middleware-API durchgeführt werden können? Die Antwort lautet ja.
Die Erstellung der Hash-Tabelle ist offensichtlich ein Fall für Vorverarbeitung und Automatisierung. Mithilfe eines Cron-Jobs können neue Artikel über Nacht aus den Livingdocs-Datenbanken abgerufen und der Hash-Tabelle hinzugefügt werden. Bestehende Artikel können auf die gleiche Weise aktualisiert werden. Dieser Prozess sollte Teil der Caching-Strategie sein, um die Reaktionszeit des Systems zu beschleunigen.
Abfragen an die OpenAI-API könnten auch verwendet werden, um AI-Funktionen mithilfe eines Cron-Jobs vorab zu berechnen. Beispielsweise könnte ein Cron-Job einmal pro Woche die SEO-Tags für alle Artikel aktualisieren. Dieser Prozess könnte auf nicht-veröffentlichte Artikel beschränkt sein.
Automatisierung und Vorverarbeitung erfordern zudem eine anwendungsfallspezifische Analyse und Rücksprache mit dem Kunden.
Alternative Ansätze
Ein weiterer Ansatz, der während eines Meetings geäußert wurde, besteht darin, ein kostenloses KI-Modell anstelle von OpenAI zu verwenden. Das reduziert die Kosten auf null, löst aber nicht die Zeitprobleme.







