

Produktfragen schneller und zielgerichteter mit ChatGPT beantworten
Gerade Unternehmen in der Produktentwicklung stehen oft vor der Herausforderung, dass sie ihre Kund*innen im Umgang mit ihren Produkten schulen müssen. Das klassische Element dazu ist häufig ein Handbuch (aka User Manual, Betriebshandbuch, etc.).
Generative AI-Modelle wie ChatGPT bieten inzwischen völlig neue und innovative Möglichkeiten, wie wir Wissen erlangen, teilen und anwenden können. Warum also nicht auch die erwähnten Handbücher mit ChatGPT durchsuchen?!
Unsere Hypothese ist hierbei, dass Fragen von Usern in Bezug auf Produkte schneller und zielgerichteter beantwortet werden als mittels Durchsuchen klassischer User Manuals.
Entwicklung eines Prototypen
Bevor es losgeht, müssen noch folgende Fragen analysiert und geklärt werden:
-
Wie können Modelle in die Lage versetzt werden, Fragen zu Handbüchern präzise zu beantworten?
-
Wie kann sichergestellt werden, dass juristisch wichtige Informationen (z. B. Sicherheits- und Warnhinweise) immer in der Antwort enthalten sind?
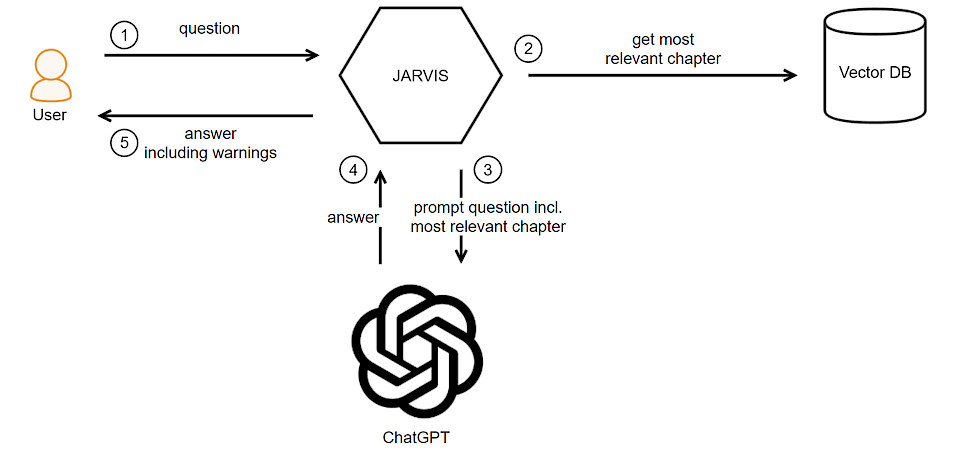
Um unsere Hypothese zu prüfen, haben wir den Prototypen „Jarvis“ entwickelt, der im Hintergrund das Large Language Model (LLM) von ChatGPT-3.5 verwendet. Die Antworten sollten möglichst präzise sein und Halluzinationen vermieden werden. Nach Evaluation der aktuellen technischen Ansätze haben wir uns für die Umsetzung von Retrieval Augmented Generation (RAG) entschieden.
Dieser Ansatz integriert Retrieval-Techniken, um relevante Informationen aus einer Wissensdatenbank abzurufen. Diese werden dann wiederum von einem generativen Modell verwendet, um spezifische Antworten zu generieren.
Dies läuft wie folgt ab:
-
Eingabe der Anfrage: Ein*e Benutzer*in stellt eine Frage in natürlicher Sprache.
-
Retrieval (Abruf): Das System verwendet eine Retrieval- oder Suchmethode, um relevante Textfragmente aus einer Wissensdatenbank abzurufen, die als Antwort auf die Anfrage dienen könnten. Diese Texte werden aufgrund ihrer Relevanz und Verbindung zur Anfrage ausgewählt.
-
Generierung der Antwort: ChatGPT nutzt die abgerufenen Informationen, um eine präzise und kontextuell angepasste Antwort zu generieren. Das Modell kann dabei den abgerufenen Text analysieren und eine passende Antwort formen, die der ursprünglichen Anfrage entspricht.
-
Ausgabe der Antwort: Die generierte Antwort wird der Benutzer*in präsentiert, um die gestellte Anfrage zu beantworten.
Um die Flexibilität beim Austausch der verschiedenen Elemente von Jarvis zu gewährleisten, haben wir uns für eine hexagonale Architektur entschieden. Jarvis wird über eine grafische Benutzeroberfläche (GUI) bedient und ist mit einem Datenbankadapter sowie einem KI-Adapter ausgestattet.
Die Datenbank als Wissensbasis ist das Herzstück von Jarvis. Dort werden Bestandteile der zu analysierenden Handbücher als Vektoreinbettungen (vector embeddings) gespeichert.
Vektoreinbettungen sind eine Art Datendarstellung, die semantische Informationen enthält. Einbettungen werden von KI-Modellen generiert und verfügen über eine Vielzahl von Attributen. Diese Attribute stellen unterschiedliche Dimensionen der Daten dar, die für das Verständnis von Mustern, Beziehungen und zugrunde liegenden Strukturen unerlässlich sind.
Eine Einbettung ist daher ein Vektor und der Abstand zwischen zwei Vektoren misst ihre Beziehung. Kleine Abstände deuten auf eine hohe Verwandtschaft hin, große Abstände auf eine geringe Verwandtschaft.
Diese Einbettungen und die Textstücke haben wir in der Open-Source-Vektordatenbank Chroma gespeichert und als Suchalgorithmus Kosinus-Ähnlichkeit eingestellt. Der Vorteil von Kosinus-Ähnlichkeit besteht darin, dass sie nicht von den Längen der Vektoren, sondern nur von deren Winkel abhängt.

Segmentierung in "Chunks" für die Datenbankbefüllung
Für die Befüllung dieser Datenbank müssen die Handbücher zunächst in kleinere Segmente, sogenannte Chunks, unterteilt werden. Die Identifizierung passender Abschnitte (wie Kapitel, Abschnitte oder Paragraphen) ist dabei von entscheidender Bedeutung.
Wir haben die Handbücher entlang der Kapitelgrenzen segmentiert. So stellen wir sicher, dass auch die Sicherheits- und Warnhinweise, die mit den Kapiteln verbunden sind, in der Datenbank gespeichert werden. Dies ermöglicht später die korrekte Ausgabe in Verbindung mit den entsprechenden Antworten.
Wenn man nun eine Frage an Jarvis stellt, wird als erstes eine Vektoreinbettung erstellt, um den relevanten Text in der Vektordatenbank zu finden. Somit ist also das relevante Kapitel aus dem Handbuch gefunden.
Dieses Kapitel sowie die Frage wird dann an ChatGPT mit einem bestimmten Prompt gesendet. ChatGPT beantwortet die Frage mithilfe des Textes aus dem Kapitel. Dabei soll ChatGPT auch alle Warn- und Sicherheitshinweise auflisten. Aufgrund der Token-Begrenzung (4000 bei GPT-3.5) wird die Antwort leider meistens abgeschnitten.
Es stellte sich heraus, dass Prompt, Frage und relevantes Kapitel nicht mehr viele Token für die Antwort übrigließ. Ein Upgrade auf GPT-4 Turbo ist empfehlenswert, da die Tokengröße hier bei 128.000 liegt.
Trennung von Anleitung und Hinweisen
Wir sind daher zu dem Schluss gekommen, dass die Kapitel in den eigentlichen Anleitungstexten und die dazugehörigen Sicherheits- und Warnhinweise getrennt werden müssen.
ChatGPT erhält jetzt nur noch den Anleitungstext, auf dessen Basis die Antwort gegeben wird. Jarvis fügt anschließend alle Hinweise an. Hierbei ist es wiederum entscheidend, wie die Handbücher unterteilt werden.
Die Chunks sollten in sich logisch geschlossen sein, also zum Beispiel nur eine bestimmte Funktion oder einen Teil erklären. Chunks sollten außerdem mit Metadaten versehen werden, damit der relevante Text in der Vektordatenbank gefunden werden kann.
Erkenntnisse dank Jarvis
Bestätigung der Hypothese
Unsere Hypothese, nach der User mithilfe von AI schnell und zielgerichtet Fragen zu Produkten basierend auf dessen Handbüchern beantwortet bekommen, hat sich bestätigt.
Folgende weitere Erkenntnisse haben wir aus unserem Jarvis-Prototypen gewinnen können:
-
Die Antwortzeit betrug je nach Auslastung der OpenAI-Server zwischen 10 Sekunden und 1 Minute, diese Antwortzeit hängt allerdings massiv vom verwendeten Modell ab. Der Vorteil ist, dass man Antworten bei ähnlichen Fragen auch cachen kann, wodurch die Antwortzeit quasi entfällt.
-
Der Import eines umfangreichen Handbuchs in die Vektordatenbank dauerte unter 2 Minuten.
-
Die Sicherheits- und Warnhinweise können zuverlässig an die Antworten angefügt werden und sollten damit auch juristischen Anforderungen genügen.
-
Halluzinationen sind de facto ausgeschlossen. Zum einen da die Antwort aus dem direkt mit der Frage mitgegebenen Kapitel stammt. Zum anderen, weil die Sicherheits- und Warnhinweise immer an die Antwort zum jeweiligen Kapitel angefügt werden.
-
Die Qualität der Input Daten ist entscheidend, denn die Handbücher müssen in sinnvolle Chunks unterteilt werden können - und das möglichst automatisiert.
-
Der Prototyp behandelt nur Text, allerdings beinhalten viele Handbücher auch Bilder und Symbole. Sofern Bilder und Symbole im Text mit Platzhaltern versehen sind, können diese ebenfalls zur Antwort ergänzt und hinzugefügt werden. Auch hier kann ein Upgrade zu GPT-4 Turbo lohnenswert sein, da es auch Bilder und Symbole interpretieren kann.
Was sind die nächsten Schritte?
Verbesserung durch Finetuning
Damit ein Hersteller viele Handbücher mithilfe von AI analysieren kann, müssen diese eingelesen werden. Dazu gibt es neben der hier gezeigten Methode auch die Möglichkeit des Finetunings.
Durch das Feintuning – beispielsweise in GPT-4 – kann das Modell für bestimmte Fachgebiete spezialisiert werden. So können präzisere und relevantere Antworten erzielt werden. Insbesondere sollte für diesen Anwendungsfall Reinforcement Learning from Human Feedback genauer evaluiert werden.
Durch Feintuning kann die Leistung des Modells in spezifischen Metriken wie Genauigkeit, Kohärenz oder Verständnis verbessert werden. Gleichzeitig wird auch die Anpassungsfähigkeit an neue Daten gewährleistet.
Noch weiter geht OpenAI mit der Einführung von GPTs. Diese customized GPT-Modelle können auf ein spezifisches Fachgebiet trainiert werden. Diese Modelle können anschließend auch über einen Marketplace der Öffentlichkeit angeboten oder als internes Modell verwendet werden.
Allerdings muss auch in diesem Fall ein Mechanismus wie in Jarvis eingebaut werden, damit Sicherheits- und Warnhinweise zuverlässig mit ausgegeben werden.
Fazit zur weiteren Nutzung
Generative AI-Modelle wie ChatGPT bieten gerade im Bereich User Interaction völlig neue Möglichkeiten. Usern werden mithilfe natürlicher Sprache schnell und zielgerichtet Fragen beantwortet. Auch juristische Anforderungen zu Sicherheits- und Warnhinweisen können zuverlässig eingehalten werden.
Es ist also möglich und empfehlenswert, Handbücher mit ChatGPT zu durchsuchen. Jetzt gilt es zukünftig, Erfahrungen mit dieser neuen Technologie zu sammeln und den Umgang, Input und Output so zu verbessern.







